
 快捷导航
快捷导航 
时间:2023-07-10 02:26:02来源:界面新闻
界面新闻记者 | 李京亚
2018年,首届世界人工智能大会从上海徐汇区开幕,五年间,徐汇的人工智能产业从无到有,今年跨过了1000亿的门槛,已成为上海首个人工智能发展的集聚区。目前,徐汇聚集了200多家相关企业,围绕大模型的突破与探索,展露出厚积薄发的底气。
7月8日,为期三天的世界人工智能WAIC大会在上海闭幕。本次大会参展企业超过400家,比去年翻番,展馆面积5万平方米,远超去年。这是有史以来主题词最突出的一届人工智能大会,绝大多数论坛围绕大模型展开,30余个人工智能大模型先后于展区和各大论坛亮相,8成与会人士的讨论内容都由大模型导入或者围绕其展开。
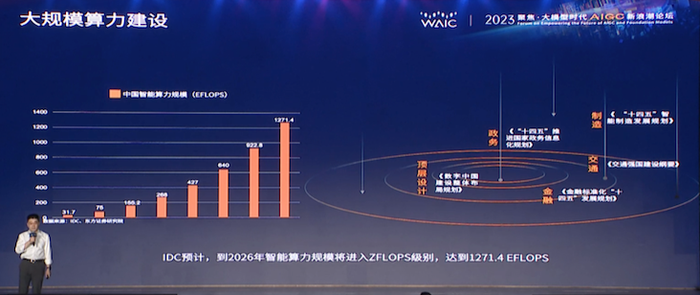
ChatGPT横空出世已有半年,算力、数据、基础设施是围绕其间的核心议题,清华大学电子工程系主任汪玉就在本次大会的开场的核心论坛上对大模型落地的三大挑战作出总结,一是领域部署成本高;二是模型算力缺口大,如果中国14亿人每个都用大模型去跑,总共需要的算力跟目前所拥有的差了三个数量级,需要让单位能量提供更高算力;第三是国产芯片生态需要扩张和构建,使得绝大多数我们自己的芯片能够被用起来。
但与之相映成趣的是,在WAIC上,透过更多业界的发声,我们发现一些核心趋势已在悄然生变。
首当其冲的判断是,算力成本开始持续下降,而且下降速度快于大模型的规模扩张。

“2020年,训练一个GPT3大模型,需要450万美金;2022年,这个量级变为45万美金;上周的最新变化是,在美国他们使用3584张H100(NVIDIA的AI高端显卡) 训练GPT3,一共需要11分钟,整体开销2万美金。”九章云极的联合创始人尚明栋在7日《大模型时代AIGC新浪潮》的主论坛上做了组数据分享,这意味着,进入GPU(图形处理器)时代,算力将不会构成从业者进行大模型计算的鸿沟,并且更进一步看,随着国家针对算力进行顶层架构设计,模型算力缺口也有可能逐步得到解决。
如果大模型能顺利运行在资源受限的设备上,就能更好的普惠大众,也基于此,芯片创业公司是本次大会展台环节的主力军,燧原科技、登临科技、翰博半导体、曙光、昆仑芯、拟未科技(Graphcore)、算能等公司悉数登场,纷纷展示出各自产品布局和生态进展。总体来看,以本次大会为节点,国内AI芯片的商业落地在大模型风起半年内已取得不浅进展。以昆仑芯为例,昆仑芯展示的第二代AI芯片是国内首款采用显存的通用芯片,能通过底层技术优化将通用计算核心算力提升2-3倍。
“大模型的需求变化以周计在变化,从市场供需需求看,大模型和芯片类公司不是完全匹配的,券商分析师过去写报告用得应用处于算力的估测方法可能不再适用,应用除以存储大小、除以带宽,能作为投资机构估算芯片企业是否值得投资的新标准。”燧原科技副总裁高平如是说,现在是计算机体系架构的黄金时代。
WAIC现场展区几乎是大厂肌肉的秀场,华为、百度、腾讯、阿里、京东、360、网易、金山办公、中国移动、中国电信,加上第四范式、澜舟科技、衔远科技、云知声、出门问问等一众当红AI创业公司,竞相展示着围绕大模型的最新成果。但值得注意的是,相比一众闻名于世的大厂模型,学术圈的模型难掩光芒,清华大学计算机系知识工程实验室的千亿参数中英文对话模型ChatGLM-130B、复旦大学自然语言处理实验室的MOSS是展台中非常耀眼的存在,吸引了大量人群驻足。
会场之内,很多人戏称这次的人工智能大会几乎办成了清华大学的论坛,因为连续三天,大量论坛和展台都云集着来自清华的教授和创业团队。
从这些学术圈人士的与会分享可以洞察到一个最新判断,大模型的整体研发门槛在悄然降低。
已经在发生的是,大模型的兴起深刻影响了高校的研究规划,很多优秀研究生和博士生在课题选择时很多开始朝着通用人工智能方向靠拢。从人才储备变化角度,研发大模型的人才越多,短期和中长期就会导致大模型研发门槛的降低。
深圳云天励飞副总裁肖嵘在大会一场圆桌论坛上称,大模型的研发门槛不仅现在在变低,未来还会更低,“语言模型的训练语料规模已快速达到上限,未来增速不会变快,随着软件、硬件工程能力的快速提升,稍微有点实力的公司都可以训练自己的通用模型。”




