
 快捷导航
快捷导航 
时间:2023-09-20 01:33:24来源:新媒体
编者按:本文探讨了大语言模型(LLM)研究中的十大挑战,作者是Chip Huyen,她毕业于斯坦福大学,现为Claypot AI —— 一个实时机器学习平台的创始人,此前在英伟达、Snorkel AI、Netflix、Primer公司开发机器学习工具。 ”
我正目睹一个前所未有的现状:全世界如此众多的顶尖头脑,如今都投入到“使语言模型(LLMs)变得更好”这个大一统的目标中。
在与许多工业界及学术界同仁交谈之后,我试着总结出十个正在蓬勃生长的主要研究方向:
1. 减少和衡量幻觉(编者按:hallucinations,AI的幻觉,即 AI 输出中不正确或无意义的部分,尽管这类输出在句法上是合理的)
2. 优化上下文长度和上下文构建
3. 融入其他数据模态
4. 提高LLMs的速度和降低成本
5. 设计新的模型架构
6. 开发GPU替代方案
7. 提高agent的可用性
8. 改进从人类偏好中学习的能力
9. 提高聊天界面的效率
10. 为非英语语言构建LLMs
其中,前两个方向,即减少“幻觉”和“上下文学习”,可能是当下最火的方向。而我个人对第3项(多模态)、第5项(新架构)和第6项(GPU替代方案)最感兴趣。
01、减少和衡量幻觉它是指当AI模型编造虚假内容时发生的现象。
对于许多需要创造性的场景,幻觉是一种难以回避的特性。然而,对于大多数其他应用场景,它是一个缺陷。
最近我参加了一个关于LLM的讨论小组,与Dropbox、Langchain、Elastics和Anthropic等公司的人员进行了交流,他们认为,企业大规模采用LLM进行商业生产,最大的障碍就是幻觉问题。
减轻幻觉现象并开发衡量幻觉的指标,是一个蓬勃发展的研究课题,许多初创公司都专注于解决这个问题。
目前也有一些临时的方法可以减少幻觉,比如为提示添加更多的上下文、思维链、自洽性,或者要求模型的输出保持简洁。
以下是可以参考的相关演讲
·Survey of Hallucination in Natural Language Generation (Ji et al., 2022)
·How Language Model Hallucinations Can Snowball (Zhang et al., 2023)
·A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity (Bang et al., 2023)
·Contrastive Learning Reduces Hallucination in Conversations (Sun et al., 2022)
·Self-Consistency Improves Chain of Thought Reasoning in Language Models (Wang et al., 2022)
·SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models (Manakul et al., 2023)
02、优化上下文长度和上下文构建AI面对的绝大多数问题都需要上下文。
例如,如果我们问ChatGPT:“哪家越南餐厅最好?”,所需上下文可能是“在哪里”,因为越南最好的餐厅和美国最好的越南餐厅可能不同。
根据《SituatedQA》(Zhang&Choi,2021)这篇有趣的论文,相当大比例的信息寻求问题都有依赖于上下文的答案,例如,NQ-Open数据集中就有约占16.5%的问题是这一类问题。
我个人认为,对于企业应用场景来说,这个比例还可能更高。假设一家公司为客户构建了一个聊天机器人,要让这个机器人能够回答任何产品的任何客户问题,那么所需上下文,可能是客户的历史记录或该产品的信息。
因为模型是从提供给它的上下文中“学习”的,这个过程也遭称为上下文学习。
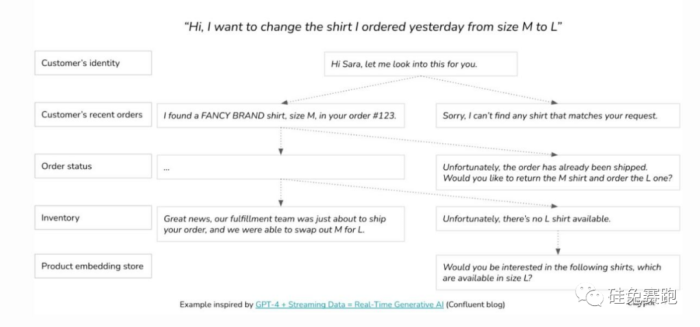
对于检索增强生成(RAG,也是LLM行业应用方向的主要方法),上下文长度尤为重要。
RAG可以简单分为两个阶段:
第一阶段:分块(也称为索引)
收集所有要供LLM使用的文档,将这些文档分成可以输入LLM以生成嵌入的块,并将这些嵌入存储在向量数据库中。
第二阶段:查询
当用户发送查询,如“我的保险政策是否可以支付这种药物X”,LLM将此查询转换为嵌入,我们称之为查询嵌入,向量数据库会获取与查询嵌入最相似的块。
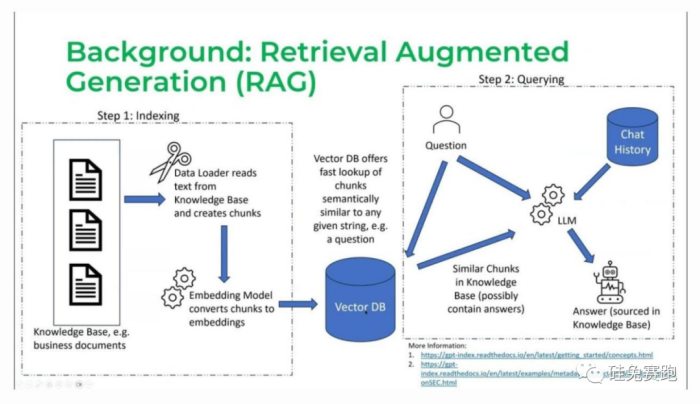
图:来自Jerry Liu关于LlamaIndex(2023)的演讲截图
上下文长度越长,我们就可以在上下文中插入更多块。但是,模型可以访问的信息越多,它的回复就会越好吗?
并不总是这样。模型可以使用多少上下文以及该模型将如何高效地使用,是两个不同的问题。与增加模型上下文长度同样重要的,是对上下文更高效的学习,后者也遭称之为“提示工程”。
最近一篇广为流传的论文,就是关于模型从索引的开头和结尾比从中间进行信息理解表现要好得多:Lost in the Middle: How Language Models Use Long Contexts (Liu et al., 2023).
03、融入其他数据模态在我看来,多模态是如此强大,却又常常遭低估。





