
 快捷导航
快捷导航 
时间:2023-05-13 10:48:04来源:互联网
5月9日,中文通用大模型综合性评测基准 SpuerCLUE(A Benchmark for Foundation Models in Chinese,下称「中文通用大模型基准」)正式发布。
在这份榜单中,除了OpenAI 在 2022 年发布的 GPT-3.5 与 2023 年发布的迭代款 GPT-4 之外,排在第三位的,是刚刚发布的星火认知大模型,即科大讯飞星火大模型(下文简称「星火大模型」)。
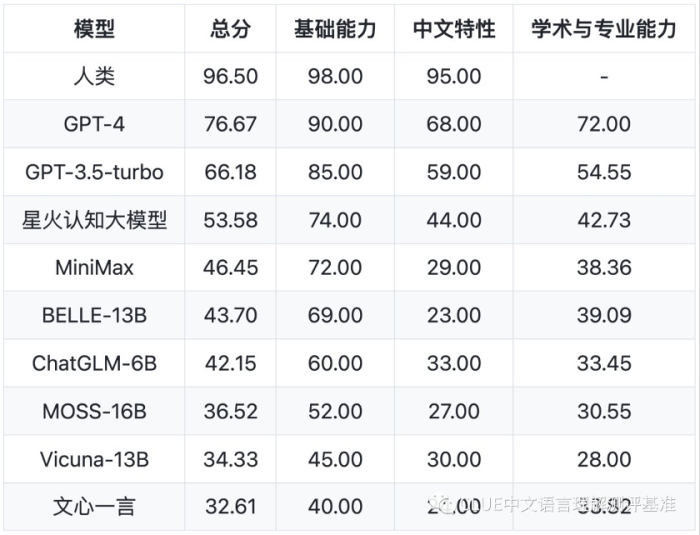
据科大讯飞介绍,星火大模型是科大讯飞历史五个多月研发所推出的大模型产品;按照科大讯飞董事长刘庆峰的说法:科大讯飞星火大模型的语言理解能力「已经走在了业界、中国同行中的最前列,跟 ChatGPT 已经非常接近」。
对于任何一个尝试发布大模型的中国科技企业来讲,在发布大模型相关的产品时,都不可避免地要被拿来与OpenAI的 ChatGPT 做对比,同时也被要求在中文语境下实现类似 ChatGPT 的通用智慧能力,这意味着大模型本身不仅要有足够的多模态交互能力,还要具备足够强的跨语种通用理解能力。 过去多个国内大模型对话产品都在这中文的综合表现上栽了跟头,拖累了整体的评价,中文语境甚至不像是「护城河」,更像是一种「诅咒」。
星火大模型在语言理解能力上,在目前的版本中就已经表现出很强的中文语境适应性:比如发布会上现场演示的。科大讯飞研究院院长刘聪曾在发布会现场提问,「俗话说男子汉大丈夫宁死不屈,但又说男子汉大丈夫要能屈能伸,请问这两句话怎么理解」以及「如果一个小伙子跟女朋友吵架了,他应该宁死不屈还是能屈能伸呢」这样的辩证问题,星火大模型均出色地理解了句子在特定场景下所代表的含义。
除了针对中文能力之外,任何大模型对话都离不开模型数据的快速迭代,这也是SuperCLUE 对模型能力的评判规则 —— 语义理解、对话、逻辑推理,以及涵盖数学、物理地理等专业知识的覆盖,以及针对中文大模型产品的特殊评判维度的原因。

当前周期内,各种大模型都处于飞速迭代更新的过程中,并且新的大模型认知对话产品仍不断涌现,因此榜单排名会跟随周期性的测试结果而变化。只有不断扩充大模型的数据集、扩大能力覆盖范围。
刘庆峰表示,文本生成和数理能力一定程度代表了一个大模型的聪明程度,“星火”大模型不仅在国内系统中显著领先,相比ChatGPT也具有一定优势;而在语言理解和知识问答方面也达到接近ChatGPT水平,处于国内领先水平;逻辑推理和代码能力已经是国内领先。
此外,在这场发布会上,科大讯飞董事长也提出了产品升级的确切时间表,他表示星火大模型还将在2023 年内,预计进行三次迭代升级,分批次增强数学能力、补足代码能力:在 6 月 9 日,首先将突破开放式问答(即实时问答),通过类搜索插件将知识抓取,再以更智能的方式自行总结并通过多轮对话能力逐一帮助用户完成指令。
到8 月 15 日,星火大模型的代码能力会上一个大台阶,此时也将更加方便开发者、合作伙伴在企业内部使用,多模态的交互能力也将正式开放给用户。最终,在今年的 10 月 24 日科大讯飞全球开发者大会期间,星火大模型在英文环境下的能力,将能够全面对标 ChatGPT,同时在中文语境体验将完全超越 ChatGPT。

商业落地是未来
截至目前,在实际测试体验中星火大模型总体表现已经足够智能,尤其是基于即时信息更新方向的新特性更是目前中文大模型对话产品中稀缺的可用性,将其评价为「中文最强」并不过分。
但除了直接面向普通用户、让大模型技术「出圈」、人人津津乐道的生成式对话机器人之外,相较于其他认知大模型,讯飞星火显然是提前一步将“应用”纳入了规划范畴。科大讯飞的“星火”还是国内率先实现应用落地的AI大模型。
星火认知大模型从最初的开启立项,其就是基于“1+N”架构来建设的,其中“N”就表示多个领域的内容,也就是应用。在发布会上,讯飞就公布了大模型在教育、办公、汽车、数字员工等多个方向的行业应用成果。
比如在教育领域,大模型就在和讯飞AI学习机结合,让AI学习机T20系列可实现中英文作文类人批改,这个批改过程是实时的,层层点评,高效精准,更可实现写作思路启发,利用AI润色技术生成片段优化参考和写作建议提升。
比如在办公领域,大模型也在和讯飞智能办公本结合,可以根据手写要点自动生成会议纪要,助力办公效能进一步提升。
比如在汽车领域,科大讯飞还有望推出搭载大模型的智能座舱,实现车内跨业务、跨场景人车自由交流。





