
 快捷导航
快捷导航 
时间:2022-12-08 22:10:02来源:界面新闻
OpenAI最初提出的GPT1,采取的是生成式预训练Transform模型(一种采用自注意力机制的深度学习模型),此后整个GPT系列都贯彻了这一谷歌2017年提出,经由OpenAI改造的伟大创新范式。
简要来说,GPT1的方法包含预训练和微调两个阶段,预训练遵循的是语言模型的目标,微调过程遵循的是文本生成任务的目的。
2019年,OpenAI继续提出GPT-2,所适用的任务开始锁定在语言模型。GPT2拥有和GPT1一样的模型结构,但得益于更高的数据质量和更大的数据规模,GPT-2有了惊人的生成能力。不过,其在接受音乐和讲故事等专业领域任务时表现很不好。
2020年的GPT3将GPT模型提升到全新的高度,其训练参数是GPT-2的10倍以上,技术路线上则去掉了初代GPT的微调步骤,直接输入自然语言当作指示,给GPT训练读过文字和句子后可接续问题的能力,同时包含了更为广泛的主题。
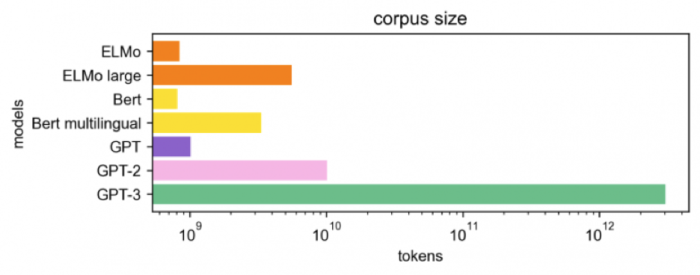
现在的ChatGPT则是由效果比GPT3更强大的GPT-3.5系列模型提供支持,这些模型使用微软Azure AI超级计算基础设施上的文本和代码数据进行训练。
具体来说,ChatGPT在一个开源数据集上进行训练,训练参数也是前代GPT3的10倍以上,还多引入了两项功能:人工标注数据和强化学习,相当于拿回了被GPT3去掉的微调步骤,实现了在与人类互动时从反馈中强化学习。
也因此,我们得以看到一个强大的ChatGPT:能理解人类不同指令的含义,会甄别高水准答案,能处理多元化的主题任务,既可以回答用户后续问题,也可以质疑错误问题和拒绝不适当的请求。
当初,GPT-3只能预测给定单词串后面的文字,而ChatGPT可以用更接近人类的思考方式参与用户的查询过程,可以根据上下文和语境,提供恰当的回答,并模拟多种人类情绪和语气,还改掉了GPT-3的回答中看似通顺,但脱离实际的毛病。
不仅如此,ChatGPT能参与到更海量的话题中来,更好的进行连续对话,有上佳的模仿能力,具备一定程度的逻辑和常识,在学术圈和科技圈人士看来时常显得博学而专业,而这些都是GPT-3所无法达到的。

尽管目前ChatGPT还存在很多语言模型中常见的局限性和不准确问题,但毋庸置疑的是,其在语言识别、判断和交互层面存在巨大优势。同属于生成式AI范畴,ChatGPT在速度上已经比DeepMind研究人员提出的聊天机器人Sparrow(麻雀)模型领先一步。
有分析指出,OpenAI一直坚定不移的只用自然文本的上文来训练模型推动了GPT3到ChatGPT的成果,其顺应了人类思考的逻辑,最终由量变推动了质变。
商业模式的通路与障碍不少人已经注意到,ChatGPT的能力已经涉及到AI模型之间的合作:一位网友要求ChatGPT写一个描述女孩的文案,然后用ChatGPT生成的文案画出了女孩的图像。
除了GPT系列之外,Open AI其实另有一条多模态领域研究支线闻名于世,即今年发布的明星产品——人工智能图像生成器DALL-E2。以DaLL E2为代表的Diffusion Model(扩散模型)几乎完成了此前爆火的AIGC(人工智能生成内容)领域的“大一统”,为AI绘画树立了全新标杆。
顶级技术能力之外,OpenAI能抢在谷歌和Meta之前重新书写AIGC版图,与其精细化的布局相关。
OpenAI月内的两笔收购都切中AIGC的增长点交叉地带,一桩投给了音频转录编辑器Descript ,一桩落子在AI笔记应用Mem。前者的处理场景刚好是文本、图片、音频以及视频,后者的技术底座是Transfomer模型,与ChatGPT同源。也就是说,OpenAI在打造自身处理下游任务的能力的同时,也在寻觅能承载下游任务的容器。
OpenAI的研究领域包括机器学习、自然语言处理和强化学习,其能在短短几年间迅速崛起,与创始人奥特曼对AI的创意性理解力密切相关:“十年前的传统观点认为,人工智能首先会影响体力劳动,然后是认知劳动,再然后,也许有一天可以做创造性的工作。现在看起来,它会以相反的顺序进行。”





